Pass Summit 2019 PreCon Day 2: The SQL Server 2019 Workshop with Bob Ward
I am still at PASS Summit in Seattle, USA and today was the second day of preconference sessions. I took the SQL Server 2019 Workshop by Bob Ward and would like to share a few things. As with my previous post on Day 1 please be kind in your judgement…it has been a long day and I am just gonna write about some short and most impressive takeaways.
So first of all, what was that all about? It was nothing less than a guided tour through the new features of SQL Server 2019. The tour guide was the fabuluous Bob Ward, Principal Architect for SQL Server at Microsoft or let me put it differently somebody who knows SQL Server by heart and is right at the center of all innovation coming into the product. I met him already at SQL Saturday in Munich in October and was quite honored that he remembered me right the moment I walked into the room and welcomed me with a charming ironic “Long time no see” :-). He presented all day through but also had his colleagues with him and so I got the chance to also meet great Pedro Lopes (Senior Program Manager focusing on Performance).
Here’s a nice photo of me and the great guys from the SQL Server Product team as a true “thumbnail”:

The programme was to learn about new SQL Server features and doing some labs on your own as well. The complete workshop is available open source at Github. Being at the precon had the advantage to use an Azure VM to do all the labs inside (and even advanced stuff such as Kubernetes) and of course having Bob Ward leading through the material and available for Q&A.
Enough introduction…so what are the key takeaways for me today?
Security
Data Classification
In 2019 you can add your own data classification categories. That’s quite interesting for me because I already undertook the challenge of data classification in SQL 2014 and soon decided to add my own metadata tables to do it because the out of the box classification categories where not flexible enough. So why should you care? After having populated the information about sensitive columns with personal identifiable information (PII) you can then run an audit to see where this information when and by whom that information gets used. Neat solution.
Wanna learn more? Have a look at the workbook (Chapter 3.1 and slightly before).
Accelerated Database Recovery
This is a game changer for rollbacks and more efficient transaction log handling. Enabling Accelerated Database Recovery you use a persistent version store in your database to speed up rollbacks respectively the undo phase during crash recovery (typically done at SQL Server startup). There’s a great demo in this workbook.
Things to consider: This capability does of course come with a cost (there’s no free lunch).
- The feature takes space in your database to store the version in the persisted version store (you can define a separat filegroup for that)
- COMMIT-Performance is not optimized and might degrade a bit…however ROLLBACK-Performance and the number of entries generated in the transaction log during a ROLLBACK are improved dramatically and the log can be truncated every time it needs to be as we keep track of the transactions in the persisted version store (there will no “ACTIVE TRANSACTION” show up als log_reusage_wait_reason). For all the things to be considered please consult the Whitepaper and test the feature thoroughly before implementing it in production.
- If you are using versioning for other purposes such as the transaction isolation level read committed snapshot (RCSI) the version store will move from tempdb to the persistent version store for rollbacks. That’s great in terms that there is no overhead to that however if you happen to run a failover cluster and chose local NVMe drives for tempdb (as I did) these fastet drives cannot be used anymore for versioning and performance might degrad a bit (you still have to test this…which I will do later this year).
So here’s the slide from Bob’s Presentation nailing the things described:

UTF-8 Support in SQL Server
This is quite new and I had a great talk to Pedro Lopes right before lunch about it. SQL Server now offers you a UTF-8 collation to store VARCHAR values in. UTF-8 should probably be the right choice for the western world being able to adress internationalization while storing data efficiently for western use cases. Pedro Lopes did a nice writeup on MSDN about things to consider. He first had to bust some myths about unicode at my side…this is definitely something I will investigate further with a migration to SQL Server 2019.
SQL Language Extensions (aka Modern Data Platform)
In this workbook Bob Ward demoed Language Extension features. The idea is that you can basically now include any language into SQL Server and call it using sp_execute_externalscript. This approach has been around since SQL 2016 starting with R, has been further developed with the ability to use Python in SQL 2017 and now is basically open for pretty every programming language. So why would you like to have a programming language support resp. integration within your database?
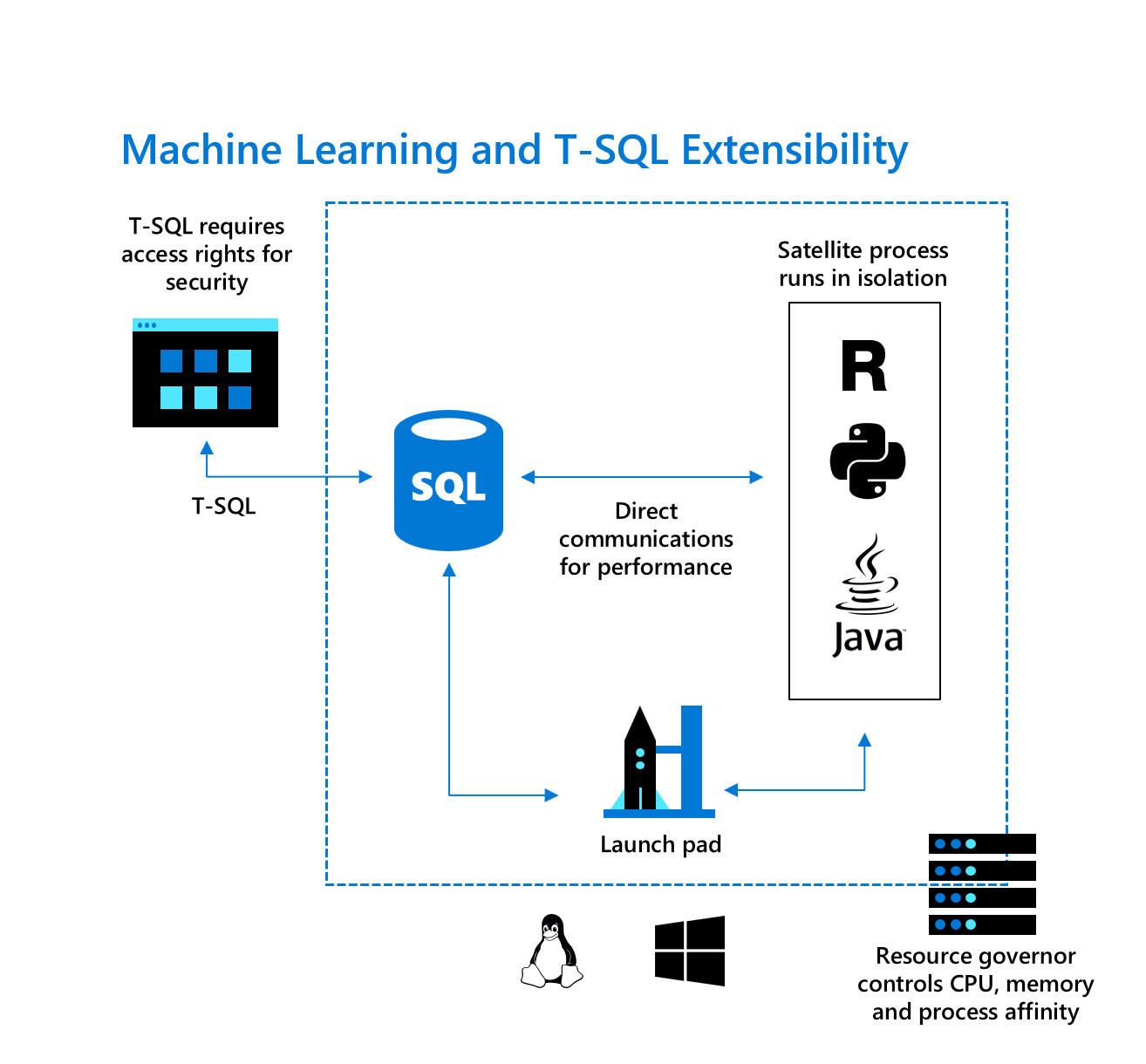
That’s the point where I am a little bit skeptic and sorry I go here on a small rant…. The example shown was yeah you could do regular expression matching. This is a point SQL Server doesn’t address natively for years now and to be honest I am not convinced that exactly this is the use case for language extensions. Many of us already have mechanisms around involving CLR do regex matching. That works and can be used further. In detail Language Extensions are a bit more flexible than CLR in terms that they don’t run within the SQL Server process but rather via a launchpad service. Regarding regex matching I have the strong opion, that there should be a native T-SQL command offering this….but there doesn’t seem to be something like that in sight. Instead we could now use R, Python, Java whatever….this is still somehow crazy if you think that you don’t want to do fancy stuff and might just set that up to do that ****** regex matching.
So having that said there might still be use cases for the feature and Bob Ward even could disarm another argument I borrowed from Brent Ozar:
You’re dead-set on doing machine learning & R in SQL Server – I know it’s trendy for data folks to do this, but remember, you’re spending $2,000 to $7,000 per core for SQL Server licensing to do this.
So you licensed that shiny SQL Server and now you are running R or Python Scripts on it where you could have run them on a different machine without spending licensing bucks on cores. Interestingly enough Bob Ward answered, that you could work your way around with affinity settings….executing externalScript Workload on additional cores which are not licensed for and therefore used by the SQL Server Engine itself.
Docker and the whole k8s thing
Hey wow I love SQL Server on Docker. Bob Ward already gave a terrific session on that at SQL Saturday in Munich and I think that SQL Server on Docker is perfect for personal demo enviroments. You can easily and quickly spin up a SQL Server without caring too much about administering the underlying linux machine.
Times running and I have to go to bed…so sorry I will not write much about docker instead that it is just great…have a look for yourself in this workshop.
The exciting thing which blew my mind today was about setting up a k8s Cluster. What the heck is k8s? k8s stands for Kubernetes, which is a container orchestrator (k then 8 characters and an s)…sometimes abbreviations are suprisingly silly ;-).
And what do you do in Kubernetes? You are basically generating a config file to tell the orchestrator how to configure your environment. There’s a funny explanation video for kids on Youtube.
Kubernetes can handle high availability scenarios….your container (or Kubernete’s slang pod [can have multiple containers]) dies and is restarted on another compute node.
And that was the real wow-effect from the workshop configuring Kubernetes in Azure and achieving such a failover scenario. Now I could boast with that knowledge to participate in bullshit bingo with technical management regarding this very hype technology…but to be honest I am not the guy to do that :-). But it’s great having seen that.
Key takeaway for me from Bob Ward regarding Kubernetes (or the alternative OpenShift) is that you should have a kubernetes expert if you will be using it yourself in the open source version (you virtually have to specify the failover handling yourself, which can get quite complicated) or you should go with a cloud offer in Azure or AWS respectively use a well established product like OpenShift or Rancher in an on-prem-scenario where you can buy consulting services for and have full support.
I see that being much interesting for development scenarios offering every developer her own container and orchestrating them to be built on a central development server. However I would rather just start building docker containers using compose first and afterwards move to Kubernetes if I handled the first part well already.
Big data clusters
This was the part of the demo where I kind of decoupled because it seemed so far away from my current set-up.
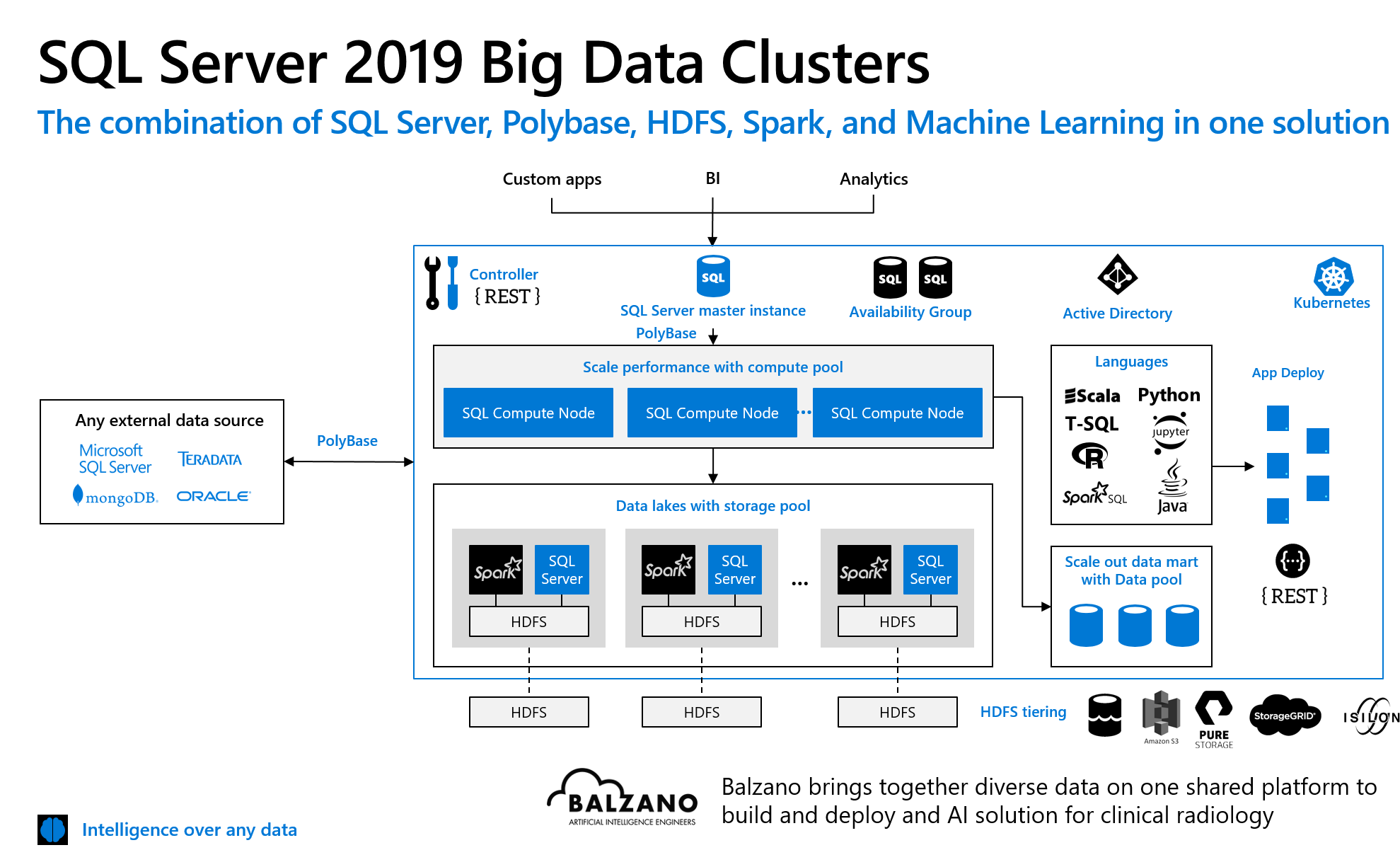
If Docker and Kubernetes wasn’t already challenging enough, take a Data Lake, Spark, Polybase (didn’t explain that…sorry but the workbooks do) and availability groups and combine them into a big solution for machine learning with the support of both Hadoop and SQL Server. Main selling point is a end-to-end-solution for companies regarding machine learning avoiding that machine learning solutions are scattered throughout the company on data scientist’s computers but rather are in a central security-governed environment. Wow that’s great art!
I also noted something else….my wife is a software developer and in her job she has to know a lot of frameworks like Spring, Bootstrap whatsoever. Being a data person in SQL server (especially within the SQL engine) the world has been quite more lucid. Now with Big Data Clusters there are suddenly different frameworks present as well such as curl, livvy, yarn and whatever else. I know I am being quite unspecific and throwing different things into the same box…but it’s late whatsoever. Long story short: Big data clusters are an impressive thing and nice to have seen once but definitely nothing which will be relevant for me and my work in the next year.
Miscellaneous
SSMS tip: Increase font sizes (esp. Object Explorer) for presenting
If you want to show something font sizes in SSMS are typically to small for people to follow. In the old days you had to go to the Options and adjust the sizes there. Since SSMS 17 we do at least have a nice zoom option within the query editor. However font size in Object Explorer stays the same.
Check that out.. Type “presentOn” in the Quick Launch bar…you even just have to type “pres” for auto complete to kick in.
Enjoy the difference..bigger font size in Object Explorer.
To roll it back use “RestoreDefaultFonts” in the Quick Launch Bar.
Here’s a nice blog post that already describes that feature thouroughly.
2 thoughts on “Pass Summit 2019 PreCon Day 2: The SQL Server 2019 Workshop with Bob Ward”
“SSMS tip: Increase font sizes (esp. Object Explorer) for presenting” how do you turn it off again . . .
Good catch. I excpected “PresentOff” however unlogical as it is the opposite command is named “RestoreDefaultFonts”.